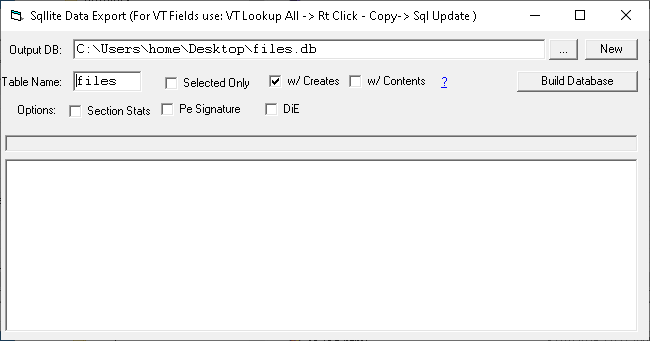
SQL Export (frmSqlExport2) writes a full structured analysis of a file set to a SQLite database, prepared-statement style. It's the right-click hand-off when ad-hoc reporting from the listview menus isn't enough — once the data's in SQLite, you can answer arbitrary questions about a sample collection with a few SELECTs.
The dialog's init takes one of three parent forms:
Recursive listview. Selected Only disabled (the recursive UI doesn't track selection the same way).
Output DB path at top, table name and option checkboxes in the middle, build status log at the bottom. The default DB path is %Desktop%\<tablename>.db, refreshed as the table name changes (until you edit the path manually).
Options
Option
Effect
Table Name
The base name for the table set. Default files. The actual tables created are <name>, <name>_sects, <name>_res, <name>_exp.
Output DB
Path to the .db file. Auto-fills as %Desktop%\<tablename>.db; click ... to browse or New to choose a fresh path.
w/ Creates
When checked (default), drops existing tables and recreates them before inserting. Uncheck to append to an existing schema.
Selected Only
(frmHash only) Only export rows that are selected in the parent listview.
Section Stats
Populate the _sects child table with one row per PE section (entropy, CRC32, raw/virtual address and size, characteristics, EP-section flag).
Pe Signature
Run Authenticode verification per file and store the result, plus the signer's subject/issuer/serial.
DiE
Run Detect It Easy per file, store its output in the die column.
w/ Contents
Read text files into the contents column. Binary files (NUL byte in the first 1024 bytes) are stored as NULL. Files larger than 10 MB are skipped. UTF-8, UTF-16 LE, and UTF-16 BE BOMs are detected; no BOM defaults to UTF-8 (handles ASCII as a strict subset).
Schema
Four tables are created. The main table is one row per file; the three child tables join back via the hash column.
<tableName> — one row per file
Column
Type
Source
firstSeen, ssz, vt, detects, subs, date
TEXT/INT
Reserved for VT enrichment — populated by the VT Lookup All → Copy → Sql Update chain in Hash Files, not by this dialog directly.
size
INT
File size in bytes.
fname
TEXT
Base file name.
path
TEXT
Full path.
details
TEXT
Reserved.
hash, sha256
TEXT
MD5 (primary join key) and SHA256.
compiled
TEXT
PE compile-date string (or content-type for non-PE).
sectCnt, sects
INT/TEXT
PE section count and concatenated section-name list.
die
TEXT
Detect It Easy output (when DiE option is on).
pdb
TEXT
Path from the debug directory.
expCnt, exports
INT/TEXT
Export count and the dumped export-name list.
resCnt, resSize, resNames
INT/INT/TEXT
Resource count, total size, and concatenated names.
imphash
TEXT
Mandiant-style import hash.
pever, fileProps, rich
TEXT
PE version-info report, Win32 file-info dump, decoded Rich-header dump.
ep, epSect, epSectIndex
TEXT/TEXT/INT
Entry point, the section it lives in, and that section's index.
is32bit, isDotnet, isDll
INT
Bool flags.
importDlls
TEXT
Newline-joined list of imported DLL names (no functions).
Authenticode result (when Pe Signature option is on).
contents
TEXT
Decoded text file contents (when w/ Contents is on); NULL for binaries.
<tableName>_sects — one row per PE section
Column
Description
hash
Joins to main table.
i
Section index.
name
Section name.
virtAddr, virtSz
VA and size, hex strings.
rawOff, rawSz
File offset and raw size, hex strings.
flags, flagNames
Characteristics as hex and as decoded flag names.
hasEP
1 if this section contains the entry point.
entropy, crc32
Per-section, computed on demand by the section accessor.
<tableName>_res — one row per resource
Column
Description
hash
Joins to main table.
rva, size, ssize
RVA, byte size, and human-readable size.
codepage
Resource code page.
entropy
Per-resource entropy.
path
Resource type/name/lang path.
<tableName>_exp — one row per exported function
Column
Description
hash
Joins to main table.
offset
Function address (hex).
name
Exported name.
ordinal
Export ordinal.
How the export runs
The build is prepared-statement based for speed: one INSERT per table is prepared at the start, then re-bound and re-executed per file/section/resource/export. Errors per row are swallowed and logged into the bottom listbox — one bad file doesn't abort the run.
The progress bar tracks per-file progress; the listbox at the bottom is the running build log. The form caption shows processed / total while running.
Note: Statement-handle ordering matters. Column order in InsertMainRow binds positionally and must match the CREATE TABLE and the INSERT column list. Editing the schema means editing all three.
The contents column is hard-capped at 10 MB per file; that's a deliberate limit to keep DBs from blowing up on accidentally-included logs or archives.
VT enrichment columns (vt, detects, subs, firstSeen, ssz, date) are present in the schema but populated separately — this dialog doesn't talk to VT itself. The header in the form caption ("For VT Fields use: VT Lookup All -> Rt Click - Copy-> Sql Update") points at the chain.
Aborting mid-run (close the form) leaves a partial DB — everything written before the abort is committed. The listbox flags the abort.
Example queries
-- which entry-point sections show up most often (PE packers / loaders)
SELECT epSect, COUNT(*) AS cnt
FROM files
GROUP BY epSect
ORDER BY cnt DESC;
-- all imphash collisions (likely same-family code with different strings)
SELECT imphash, GROUP_CONCAT(hash, ', ') AS samples, COUNT(*) AS cnt
FROM files
GROUP BY imphash
HAVING cnt > 1;
-- section names by frequency
SELECT name, COUNT(*) AS cnt
FROM files_sects
GROUP BY name
ORDER BY cnt DESC;
-- find all signed .NET DLLs imported by anything in the set
SELECT fname, sha256, sig_subject
FROM files
WHERE isDll = 1 AND isDotnet = 1 AND sig IS NOT NULL;