JS RefactoringAuthor: David Zimmer Date: 09.09.10 - 5:34am So i spent half of my holiday weekend experimenting with writing a javascript refactoring/de-obsfuscation feature for pdf stream dumper. boy that is some code that can make your brain hurt! By the grace of god, it seems to be working and stable. 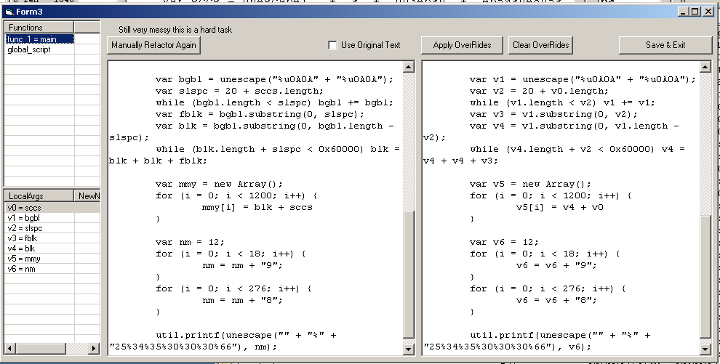
Figured i would post some details on what i learned in the process for others who are looking to take on a similar task. The first step in the process, is to first standardize the code. Luckily JS Beautifier does an awesome job of this! I have written similar things in the past and skimped on this stage and it only leads to grief. Second step is to extract all the functions from within the main script body, a placeholder is left in the original global script (they are literally exrtacted) at this stage you also parse and record the function names. third step, parse the global script and extract all global variables 4th - pre process each function and extract local variables, and function arguments. You now have collections that contains all the global functions, global variables, and then per function collections of their local variables and function arguments. Since many of these name are quite similar (ssda, assda etc) you cant just use a basic string replace because you would end up replacing portions of other strings (to bad replace doesnt have a "whole word only" option..but that would stull fail because it would have to be js syntax aware to know what a delimiter was for a word. Also if you try to cheat and sort the tokens by length (complexity) it will still fail. You have to write your own string scanner which will scan each line character by character looking for variables to mark for replacement. You have to follow the rules for js syntax. Like a variables name can be any block of letters or numbers including underscore but not starting with a numeric. The variable ends with the first char not matching this pattern. Once you have a complete token, you now have to scan each of your collections to see if its known and replace it with a unique complex marker that wont be repeated anywhere else. This token completed, you now recursivly pass the rest of that line on to the parsing function again. Once all of that is done, you do a final cycle through the lines doing a replace to change the complex unique markers to human readable simplified markers. All string replace calls you make should be minimized to working on as small a set of data as possible to minimize the chance of stomping on other data. Now that all the functions are processed, you can go back through the global script replacing the function placeholders with the updated functions. One design decision i made that I am still evaluating is that i decided not to look inside quoted strings for tokens to replace. In general this seems like a sound decision, except that obsfuscated scripts may make use of eval on quoted strings for one reason or another. Will play that one by ear. It was actually more work to program this in than leave it out. The UI i made also has a couple extra features. By parsing out the functions first, I was able to include a listview to select them individually and a button to parse them manually for targeted debugging (really good idea!) I also included a way that you can override the default local variable names on a per function basis for readability. It would also be nice to be able to override the function names and function argument variables, but really it would be best to make another class that held each variable by name with its original and override to do all of this. I just hacked it together with collections holding complex data I had to parse like new_name = org_name and new_name->override_name. Then of course you have to provide UI to handle each edit which is more than necessary for me for this project. Anyway...its not a task for the faint of heart. Especially the recursive string scanner is a real pita to debug. I have tried before to get away with less, while it increases readability, it also breaks scripts. You can get the jist of whats going on better without all the extra noise of variable names like jdfksjflksj and jdksjdksjdl but I think this one is actually exact. phew! Source code for this implementation is included in the pdf stream dumper project installer. Comments: (0) |
About Me More Blogs Main Site
|
||||||||||||||||||||||||||||